It’s just a punycode domain, it ought be rendered in Japanese:
Edit: I swear those replies weren’t there when I typed mine.
It’s just a punycode domain, it ought be rendered in Japanese:
Edit: I swear those replies weren’t there when I typed mine.


Not beating the association between AI and scams with this one.
The cheaper it is to produce slop code, the less the demand there will be to buy it. Companies will self-vend instead of buying the slop being sold. Your profit margins are someone else’s inefficiency.
When the cost to ship trash code trends toward zero, then there will not be value in shipping trash code. Companies will need to focus on software that is actually competitive (in a qualitative way) because otherwise their customers will just self-vend the slop code.
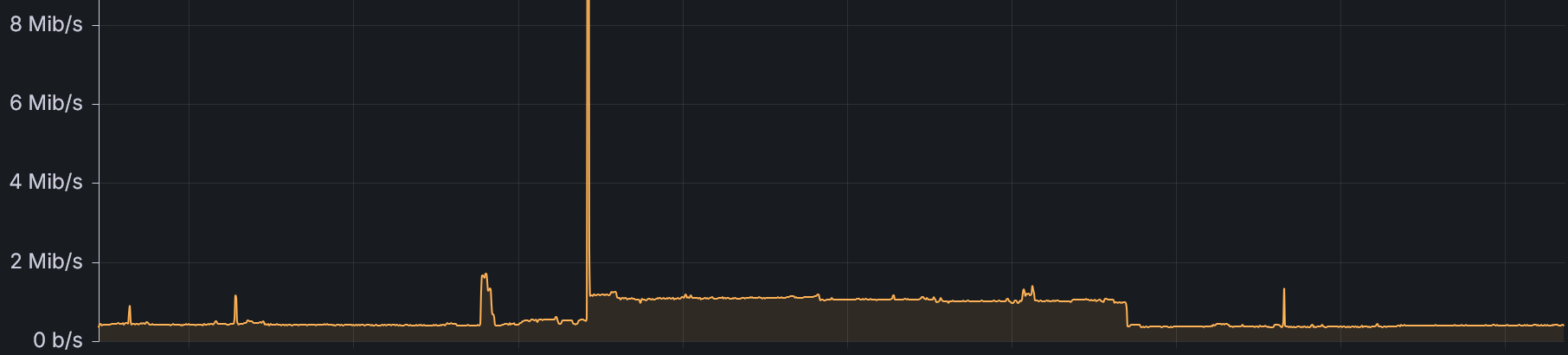
It’s was a pretty specific non standard port on UDP. It’s not even doing proper scanning since the byte sequence used isn’t one that would trigger a response challenge/ack. My guess is someone trying to DOS using an older byte sequence that used to choke/kill the server software on older versions.
The Belgian traffic? Almost entirely from a single residential IP — one box that sent over 156,000 login attempts, more than the entire country of Germany. It just sat there, hammering echo “\x6F\x6B” over and over, every single second, for weeks. Relentless.
Had a funny similar thing, there’s some weird person/people that randomly probe and attack a specific game’s community hosted dedicated servers; and one week this specific IP address out of Virginia was just hammering one of mine, with what amounts to a specific byte sequence, then an incrementing number of the packet (until it wrapped around). Then it stopped. Weird shit.

The course I’m in uses Algorithms (Fourth Edition) by Sedgwick and Wayne[1], and I consider it pretty good. A large focus is on clear implementations that demonstrate the core parts of each algorithm, without getting bogged down in specialization, which I can appreciate. The book also has very good visualizations (they call them traces) if you learn better visually. The only real downside is it’s entirely Java oriented material. But since you’re working with C# this probably isn’t a deal breaker.
The other recommendation in the thread is Introduction to Algorithms, which I’ve read chapters of (used as reference) — personally it’s ok, definitely more abstract and math heavy, so if that’s something you want or appreciate then it’s a good option.
There’s also The Art of Computer Programming by Knuth, which to me is grad level stuff, very very math heavy, but also brilliant, if you can keep up.
Theres a book, supplemental video courses, and example implementations: https://algs4.cs.princeton.edu/home ↩︎
Honestly probably a good thing long-term, lots of platforms have been dragging their heels in adopting better newer codecs, so maybe this will finally give the justification required to put in the engineering hours.
Ultimately Email is old technology, all the web frontends just get in the way more or less.
I use an email host that has roadmapped switching their frontend to one I don’t really like, so figured I’d get ahead of the curve and switch to a client that was open source and compatible with the typical standards — so I could learn it and never have to deal with another client again.
Ended up using Thunderbird, even for my old inboxes at the typical web companies
One client, all my emails in one spot, don’t have to deal with stupid UX changes being forced on users.
Not a fan of this model broadly. It discourages diverse membership and promotes cliques.
And what about when the AI owning class introduce intended bias?
It’s one the scariest outcomes possible. If people forego their reasoning and critical faculties for chat-bots. If you aren’t even the one thinking your own thoughts, who is?
It’s almost necessary at this point. At least some form of AI scraper prevention.
I had to take my public repos down a couple days ago, individuals and belligerents using botnets make blocking scrapers via normal means (user-agent/CIDR block) ineffective. So things like CloudFlare or Anubis are becoming necessary.
I think it’s a perspective thing.
Men are less likely to perceive themselves as potential SA victims (regardless of actual numbers): so the relative subjective “chance” of false accusations against them vs being victims themselves impacts their priorities.

I would say scrutability in itself doesn’t automatically make an algorithm good. “Demote everything that doesn’t support Trump” is perfectly scrutable but leads to a skewed discussion.
This is mostly getting into normative vs descriptive philosophy. If it’s scrutable that a site/instance is demoting everything non-aligned with a worldview; then on the Fediverse it’s users’ choice to leave (and part of ‘community values’).
In fact I would say any content boosting algorithm at all leads to skew and what you call sycophancy. That includes upvotes/downvotes that affect what posts users see first. So I would get rid of all that stuff and just show purely chronologically.
To some degree, yes. New Reddit is particularly bad about this, it actively buries unpopular replies (but it goes further, and doesn’t just use upvotes) — Software like Lemmy is better, you can easily set Sort by New or sort by Top as the default. There’s also no ‘Karma’ system that propagates across the site.
Sycophancy is a human trait, so it’ll always emerge in social systems; but normatively, our systems should not cater to these negative traits (e.g. Twitter).
For algorithms, anything that isn’t a straightforward scrutable way of presenting user content is bad, IMO.
Algorithms that promote engagement, monetization, and sycophants are bad.
As for community of communities, that’s how the Fediverse works — you have a home instance which communicates with other instances. An instance has (nominally) rules, and expected conduct, and is often centered around a particular interest (game dev, programming, cities or countries, etc) then these communities interact with each other.
Having home instances with shared values and a subset of the entire userbase allows for recognizing and connecting with other “local” users. The same way people would trust their immediate neighbors more than random people from the city over. It helps form webs of trust, and establish natural networks.
This is how human society has functioned up until very recently — it’s what the brain evolved to do.
We can see the consequence of systems that don’t respect that fact, sites that try catering to everyone and put us in the same tent, it destroys social regulation, you cannot possibly hope to explain yourself to tens of thousands of angry people on the Internet, nor should people be exposed to such vitriol.
It’s not the point of the article, but I think it nonetheless speaks to the power that the community-of-communities model provides.
The algorithmic content surfacing models are what primarily rot online interaction. Having all-encompassing sites is another cause. Letting people join communities with shared values, and those communities collectively deciding who they interact with, is a fundamental working model of human societies since prehistory.
Further hampered by the Steam “discussions” that are an incredibly unmoderated cesspit.
{kind=link}
There’s often a tacit acknowledgment to the poor quality of AI output, but that they do not care, the strategy is to flood the zone with so much garbage as to make it irrelevant. It’s a grift-conomy mindset, the focus is on “velocity” and “productivity” to the detriment of all else.