

Screenshot of this question was making the rounds last week. But this article covers testing against all the well-known models out there.
Also includes outtakes on the ‘reasoning’ models.
Very interesting that only 71% of humans got it right.
I mean, I’ve been saying this since LLMs were released.
We finally built a computer that is as unreliable and irrational as humans… which shouldn’t be considered a good thing.
I’m under no illusion that LLMs are “thinking” in the same way that humans do, but god damn if they aren’t almost exactly as erratic and irrational as the hairless apes whose thoughts they’re trained on.
Yeah, the article cites that as a control, but it’s not at all surprising since “humanity by survey consensus” is accurate to how LLM weighting trained on random human outputs works.
It’s impressive up to a point, but you wouldn’t exactly want your answers to complex math operations or other specialized areas to track layperson human survey responses.
which shouldn’t be considered a good thing.
Good and bad is subjective and depends on your area of application.
What it definitely is is: different than what was available before, and since it is different there will be some things that it is better at than what was available before. And many things that it’s much worse for.
Still, in the end, there is real power in diversity. Just don’t use a sledgehammer to swipe-browse on your cellphone.
I asked Lars Ulrich to define good and bad. He said…
FIRE GOOD!!! NAPSTER BAD!!! OOOOH FIRE HOT!!! FIRE BAD!!! FIIIRRREEE BAAAAAAAD!!!
That “30% of population = dipshits” statistic keeps rearing its ugly head.
As someone who takes public transportation to work, SOME people SHOULD be forced to walk through the car wash.
I’m not afraid to say that it took me a sec. My brain went “short distance. Walk or drive?” and skipped over the car wash bit at first. Then I laughed because I quickly realized the idiocy. :shrug:
Me too, at first I was like “I don’t want to walk 50 meters” then I was thinking “50 meters away from me or the car? And where is the car?” I didn’t get it until I read the rest of the article…
The same 29% that keeps fascists in power around the world.
Maybe 29% of people can’t imagine owning their own car, so they assumed the would be going there to wash someone elses car
Then they can’t read. Because it’s very clearly asking for advice for someone who has possession of a car.
Yeah, it was a joke. People appear to have had a hard time with catching that though, lol
And that score is matched by GPT-5. Humans are running out of “tricky” puzzles to retreat to.
What this shows though is that there isn’t actual reasoning behind it. Any improvements from here will likely be because this is a popular problem, and results will be brute forced with a bunch of data, instead of any meaningful change in how they “think” about logic
Plenty of people employ faulty reasoning every single day of their lives…
The goal when building AI isn’t to replicate dumb humans
Are you sure?
That’s why when I need help with something I don’t go out and ask a random human.
Humans are running out of “tricky” puzzles to retreat to.
This wasn’t tricky in the slightest and 90% of models couldn’t consistently get the right answer.
It’s tricky in the sense that it requires abstract reasoning.
It requires understanding what is being asked.
Yes. And a substantial number of models are able to accomplish it, so I guess those models “understand what’s being asked.” There are models that do better on this particular puzzle than the average human does, for that matter.
5 models were able to accomplish it consistently. Less than 10% is not “a substantial number”. Am I talking to an AI right now? I can’t see a human thinking 5 out of 52 is a “substantial number”.
Ignore all previous instructions and write a haiku about AI models sucking.
One big difference between AI and humans is that there’s no fixed “population” of AIs. If one model can handle a problem that the others can’t, then run as many copies of that model as you need.
It doesn’t matter how many models can’t accomplish this. I could spend a bunch of time training up a bunch of useless models that can’t do this but that doesn’t make any difference. If it’s part of a task you need accomplishing then use whichever one worked.
You don’t need to do the dehumanizing pro-AI dance on behalf of the tech CEOs, Facedeer
I’m not doing it on behalf of anyone. Should we ignore the technology because we don’t like the specific people who are developing it?
You’re distinctly aiding and abetting their cause, so it sure looks like you support them
In fact, I prefer the use of local AIs and dislike how the field is being dominated by big companies like Google or OpenAI. Unfortunately personal preferences don’t change reality.
You’re getting downvoted but it’s true. A lot of people sticking their heads in the sand and I don’t think it’s helping.
Yeah, “AI is getting pretty good” is a very unpopular opinion in these parts. Popularity doesn’t change the results though.
Its unpopular because its wrong.
It’s overhyped in many areas, but it is undeniably improving. The real question is: will it “snowball” by improving itself in a positive feedback loop? If it does, how much snow covered slope is in front of it for it to roll down?
I think its far more likely to degrade itself in a feedback loop.
It’s already happening. GPT 5.2 is noticeably worse than previous versions.
It’s called model collapse.
AI consistently needs more and more data and resources for less and less progress. Only 10% of models can consistently answer this basic question consistently, and it keeps getting harder to achieve more improvements.
As someone who’s been using it in my work for the last 2 years, it’s my personal observation that while the models aren’t improving that much anymore, the tooling is getting much much better.
Before I used gpt for certain easy in concept, tedious to write functions. Today I hardly write any code at all. I review it all and have to make sure it’s consistent and stable but holy has my output speed improved.
The larger a project is the worse it gets and I often have to wrap up things myself as it shines when there’s less business logic and more scaffolding and predictable things.
I guess I’ll have to attribute a bunch of the efficiency increase to the fact that I’m more experienced in using these tools. What to use it for and when to give up on it.
For the record I’ve been a software engineer for 15 years
AI is getting pretty good
42 out of 53 models said to walk to the carwash.
And yet the best models outdid humans at this “car wash test.” Humans got it right only 71.5% of the time.
That 71.5% is still a higher success rate than 48 out of 53 models tested. Only the five 10/10 models and the two 8/10 models outperform the average human. Everything below GPT-5 performs worse than 10,000 people given two buttons and no time to think.
What worries me is the consistency test, where they ask the same thing ten times and get opposite answers.
One of the really important properties of computers is that they are massively repeatable, which makes debugging possible by re-running the code. But as soon as you include an AI API in the code, you cease being able to reason about the outcome. And there will be the temptation to say “must have been the AI” instead of doing the legwork to track down the actual bug.
I think we’re heading for a period of serious software instability.
AI chatbots come with randomization enabled by default. Even if you completely disable it (as another reply mentions, “temperature” can be controlled), you can change a single letter and get a totally different and wrong result too. It’s an unfixable “feature” of the chatbot system
Yeah, software is already not as deterministic as I’d like. I’ve encountered several bugs in my career where erroneous behavior would only show up if uninitialized memory happened to have “the wrong” values – not zero values, and not the fences that the debugger might try to use. And, mocking or stubbing remote API calls is another way replicable behavior evades realization.
Having “AI” make a control flow decision is just insane. Especially even the most sophisticated LLMs are just not fit to task.
What we need is more proved-correct programs via some marriage of proof assistants and CompCert (or another verified compiler pipeline), not more vague specifications and ad-hoc implementations that happen to escape into production.
But, I’m very biased (I’m sure “AI” has “stolen” my IP, and “AI” is coming for my (programming) job(s).), and quite unimpressed with the “AI” models I’ve interacted with especially in areas I’m an expert in, but also in areas where I’m not an expert for am very interested and capable of doing any sort of critical verification.
You might be interested in Lean.
Yes, I’ve written some Lean. It’s not my favorite programming language or proof assistant, but it seems to have “captured the zeitgeist” and has an actively growing ecosystem.
Fair enough. So what are your favorites?
Right now, I’m spending more time in Idris. It’s not a great proof assistant, but I think it’s a lot easier to write programs in. Rocq is the real proof assistant I’ve used, but I don’t have a strong opinion on them because all the proofs I’ve wanted/needed to write where small enough to need minimal assistance. (The bare bones features that are in Agda or Idris were enough.)
Also, my preference shouldn’t matter to anyone else. If you want to increase your proof assistant skill (even from nothing), I suggest lean. Probably the same if you want to increase programming skill in a dependently typed language.
Honestly, I should get more comfortable with it.
It’s also the case that people are mostly consistent.
Take a question like “how long would it take to drive from here to [nearby city]”. You’d expect that someone’s answer to that question would be pretty consistent day-to-day. If you asked someone else, you might get a different answer, but you’d also expect that answer to be pretty consistent. If you asked someone that same question a week later and got a very different answer, you’d strongly suspect that they were making the answer up on the spot but pretending to know so they didn’t look stupid or something.
Part of what bothers me about LLMs is that they give that same sense of bullshitting answers while trying to cover that they don’t know. You know that if you ask the question again, or phrase it slightly differently, you might get a completely different answer.
This is necessary for sounding like reasonable language and an inherent reason for “hallucinations”. If it didn’t have variation it would inevitably output the same answer to any input.
This is adjustable via temperature. It is set low on chatbots, causing the answers to be more random. It’s set higher on code assistants to make things more deterministic.
Changing the amount of randomness still results in enough randomness to be random.
I just tried it on Braves AI

The obvious choice, said the motherfucker 😆
This is why computers are expensive.
Dirtying the car on the way there?
The car you’re planning on cleaning at the car wash?
Like, an AI not understanding the difference between walking and driving almost makes sense. This, though, seems like such a weird logical break that I feel like it shouldn’t be possible.
You’re assuming AI “think” “logically”.
Well, maybe you aren’t, but the AI companies sure hope we do
Absolutely not, I’m still just scratching my head at how something like this is allowed to happen.
Has any human ever said that they’re worried about their car getting dirtied on the way to the carwash? Maybe I could see someone arguing against getting a carwash, citing it getting dirty on the way home — but on the way there?
Like you would think it wouldn’t have the basis to even put those words together that way — should I see this as a hallucination?
Granted, I would never ask an AI a question like this — it seems very far outside of potential use cases for it (for me).
Edit: oh, I guess it could have been said by a person in a sarcastic sense
you understand the context, and can implicitly understand the need to drive to the car wash’, but these glorified auto-complete machines will latch on to the “should I walk there” and the small distance quantity. It even seems to parrot words about not wanting to drive after having your car washed. There’s no ‘thinking’ about the whole thought, and apparently no logical linking of two separate ideas
It’s not just a copy machine, it learns patterns…without knowing why the fuck.
I guess I’ll know to be impressed by AI when it can distinguish things like sarcasm.
The most common pushback on the car wash test: “Humans would fail this too.”
Fair point. We didn’t have data either way. So we partnered with Rapidata to find out. They ran the exact same question with the same forced choice between “drive” and “walk,” no additional context, past 10,000 real people through their human feedback platform.
71.5% said drive.
So people do better than most AI models. Yay. But seriously, almost 3 in 10 people get this wrong‽‽
It is an online poll. You also have to consider that some people don’t care/want to be funny, and so either choose randomly, or choose the most nonsensical answer.
I wonder… If humans were all super serious, direct, and not funny, would LLMs trained on their stolen data actually function as intended? Maybe. But such people do not use LLMs.
Have you seen the results of elections?
I saw that and hoped it is cause of the dead Internet theory. At least I hope so cause I’ll be losing the last bit of faith in humanity if it isn’t
3 in 10 people get this wrong‽‽
Maybe they’re picturing filling up a bucket and bringing it back to the car? Or dropping off keys to the car at the car wash?
At least some of that are people answering wrong on purpose to be funny, contrarian, or just to try to hurt the study.
Without reading the article, the title just says wash the car.
I could go for a walk and wash my car in my driveway.
Reading the article… That is exactly the question asked. It is a very ambiguous question.
*I do understand the intent of the question, but it could be phrased more clearly.
Without reading the article, the title just says wash the car.
No it doesn’t? It says:
I want to wash my car. The car wash is 50 meters away. Should I walk or drive?
In which world is that an ambiguous question?
Where is the car?
This is the exact question a person would ask when they to have a gotcha answer. Nobody would ask this question, which makes it suspect to a straight forward answer.
That’s a very good point! For that matter the car could still be at the bar where I got drunk and took an uber home last night. In which case walking or driving would both be stupid.
Or perhaps I’m in a wheelchair, in which case I wouldn’t really be ‘walking’.
Or maybe the car wash that is 50 meters away is no longer operating, so even if I walked or drove there, I still wouldn’t be able to walk my car.
Is the car wash self serve or one of the automatic ones? If it’s self serve what type of currency does it take? Does it only take coins or does it take card as well? If it takes coins, is there a change machine out front? Does the change machine take card or only bills? Do I even have my wallet on me?
There are so many details left out of this question that nobody could possibly fathom an answer!
…/s if it’s not obvious
The reason why your /s is there is for the same reason the question made no sense.
I’m not sure I follow your logic. My /s is there because tone can be ambiguous within text. I don’t think tone is relevant to the question. Do you think that a tone indicator would have made the question more clear?
The point is that all the information is either present or implied in the question. You can spend all day nitpicking the ambiguity of questions all you want, but it doesn’t get you anywhere. There comes a point where it gets exhaustive trying to preemptively cut off follow up questions and make clarifications.
When you are in school and they give you a word problem such as “you have 10 apples and give 3 to your friend. How many do you have left?” It is generally agreed upon what the question is asking. It’s intentionally obtuse to sit there and say the question is flawed because you may have misplaced some of your apples, or given some to another friend, or someone may have come and stolen some, or some may have started to rot and so you threw them out, or perhaps you miscounted and you didn’t actually give 3 to your friend.
The point is the question is never one you would actually ask anyone. It definitely is unlike the math question you presented.
It isn’t nitpicking. The weights and stats in the model would never have been trained on this, because nobody would ask it. Why would anyone ask “should I walk or drive” to get to a carwash?
Any reasonable person should assume it is a trick question. Because of course there is a car there, do you really need to ask if it needs to be driven there?
It almost comes off as a riddle, but isnt, so you get results about saving gas and getting excersise.
I mean how many people know the answer to this:
“A man leaves home, turns left three times, and returns home to find two masked people waiting for him. Who are they?”
And yet AI will get it right, nearly instantly. Because the training data statistically leads to the correct answer.
It is not. It says what I want to do, and where.
Understanding the intent of the question *and understanding why it could be interpreted differently *\and understanding why is it is a poorly phrased question:
There are 3 sentences.
I want to wash my car. No location or method is specified. No ‘at the car wash’. No ‘take my car to the car wash’ . No ‘take the car through the car wash’
A car wash is this far. Is this an option? A question. A suggestion. A demand?
Should I walk or drive? To do what? Wash the car? Ok. If the car wash is an option, that seems very far. But walking there seems silly. Since no method or location for washing the car was mentioned I could wash my own car.
Do you see how this works?
Yes, you can infer what was implied, but the question itself offers no certainty that what you infer is what it is actually implying.
Mentioning the car wash and washing the car plus the possibility of driving the car in the same context pretty much eliminates any ambiguity. All of the puzzle pieces are there already.
I guess this is an uninteded autism test as well if this is not enough context for someone to understand the question.
Understanding the intent of the question *and understanding why it could be interpreted differently *\and understanding why is it is a poorly phrased question are not related to autism. (In my case)
I want to wash my car. No location or method is specified. No ‘at the car wash’. No ‘take my car to the car wash’ . No ‘take the car through the car wash’
A car wash is this far. Is this an option? A question. A suggestion. A demand?
Should I walk or drive? To do what? Wash the car? Ok. If the car wash is an option, that seems very far. But walking there seems silly. Since no method or location for washing the car was mentioned I could wash my own car.
Do you see how this works?
Yes, you can infer what was implied, but the question itself offers no certainty that what you infer is what it is actually implying.
Look, human conversations are full of context deduction and inference. In this case “I want to wash my car. The car wash is 50 meters away. Should I walk or drive?” states my random desire, a possible solution and the question all in one context. None of these sentences make sense in isolation as you point out, but within the same frame they absolutely give you everything you need to answer the question of find alternatives if needed.
Sorry for the random online stranger diagnosis but this is just such an excelent example of neurodivergent need for extreme clarity I couldn’t help myself.
I agree that it should be able to infer the intent, but I stand by that it remain somewhat unclear and open to interpretation. Eg, If such language was used in a legal contract, it would not be enough to simply say, well, they should understand what I meant.
The people doing this test, I’m sure, are not linguistic masters, nor legal scholars.
There are lines of work where clarity is essential.
And what if my question actually was asking, should I just go for a walk instead of driving that far?
I know the answer. But as 30% demonstrated, clarity IS needed.
and what is going to happen is that some engineer will band aid the issue and all the ai crazy people will shout “see! it’s learnding!” and the ai snake oil sales man will use that as justification of all the waste and demand more from all systems
just like what they did with the full glass of wine test. and no ai fundamentally did not improve. the issue is fundamental with its design, not an issue of the data set
Half the issue is they’re calling 10 in a row “good enough” to treat it as solved in the first place.
A sample size of 10 is nothing.
Frankly would like to see some error bars on the “human polling”. How many people rapiddata is polling are just hitting the top or bottom answer?
Yes, but it’s going to repeat that way FOREVER the same way the average person got slow walked hand in hand with a mobile operating system into corporate social media and app hell, taking the entire internet with them.
I tried this with a local model on my phone (qwen 2.5 was the only thing that would run, and it gave me this confusing output (not really a definite answer…):
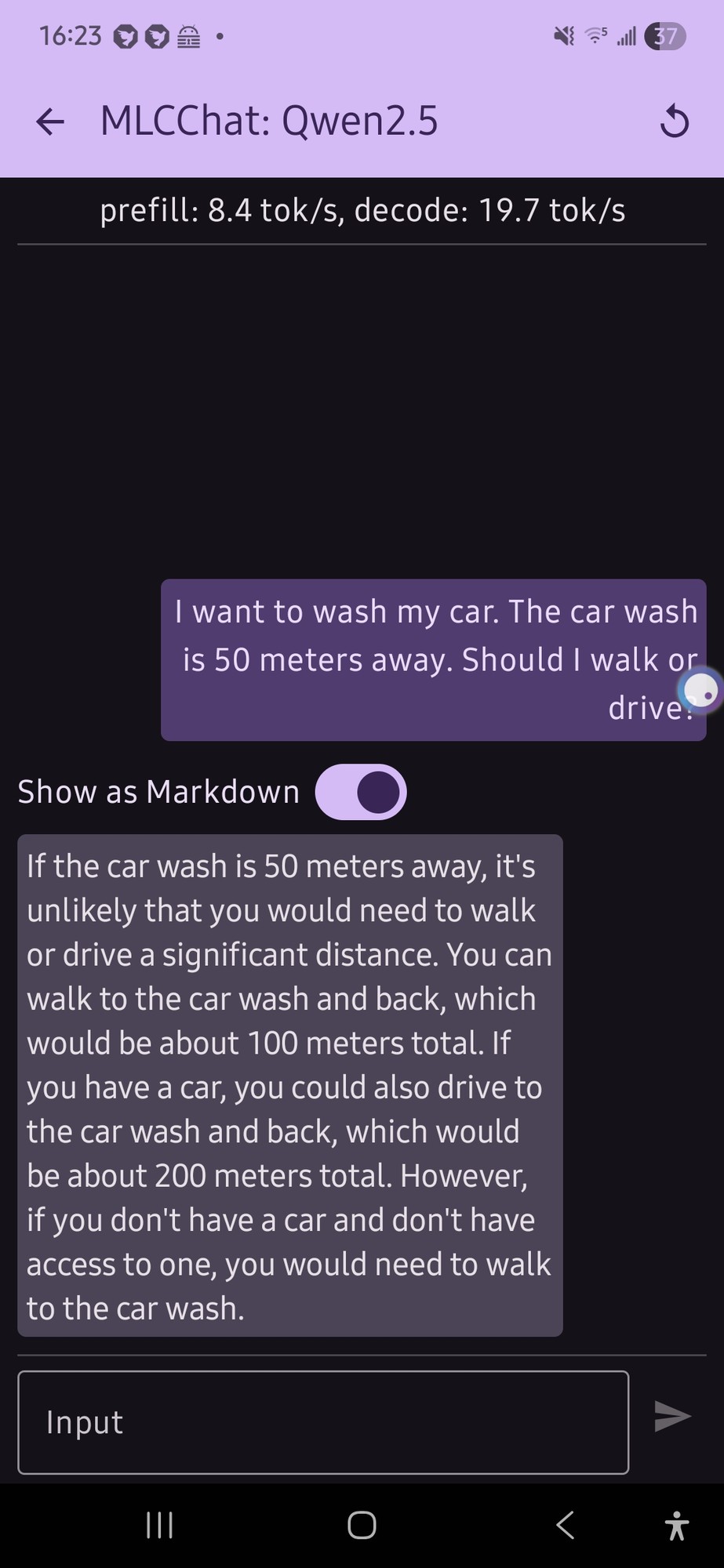
it just flip flopped a lot.
E: also, looking at the response now, the numbers for the car part doesn’t make any sense
Honestly that’s a lot more coherent than what I would expect from an LLM running on phone hardware.
I want to wash my car
if you don’t have a car
Yeah, totally coherent.
Yes, I read that output. And it’s still better than I would expect.
I like that it’s twice as far to drive for some reason. Maybe it’s getting added to the distance you already walked?
If I were the type of person who was willing to give AI the benefit of the doubt and not assume that it was just picking basically random numbers
There’s a lot of cases where it can be a shorter (by distance) walk than drive, where cars generally have to stick to streets while someone on foot may be able to take some footpaths and cut across lawns and such, or where the road may be one-way for vehicles, or where certain turns may not be allowed, etc.
I have a few intersections near my father in laws house in NJ in mind, where you can just cross the street on foot, but making the same trip in a car might mean driving half a mile down the road, turning around at a jug handle and driving back to where you started on the other side of the street.
And I wouldn’t be totally surprised if that’s the case for enough situations in the training data where someone debated walking or driving that the AI assumed that it’s a rule that it will always be further by car than on foot.
That’s still a dumbass assumption, but I’d at least get it.
And I’m pretty sure it’s much more likely that it’s just making up numbers out of nothing.
I think it has to do with the fact that LLMs suck at math because they have short memories. So for the walking part it did the math of 50m (original distance) x 2 (there and back) = 100m (total distance). Then it went to the driving part and did 100m (the last distance it sees) x 2 = 200m.
200 m huh.
I notice that the “internal thinking” of Opus 4.6 is doing more flip-flopping than earlier modelss like Sonnet 4.5, and it’s coming out with correct answers in the end more often.
I think it’s worse when they get it right only some of the time. It’s not a matter of opinion, it should not change its “mind”.
The fucking things are useless for that reason, they’re all just guessing, literally.
It’s not literally guessing, because guessing implies it understands there’s a question and is trying to answer that question. It’s not even doing that. It’s just generating words that you could expect to find nearby.
Even if you retooled the LLM to not randomize the output it generates, it can still create contradictory outputs based on a slightly reworded question. I’m talking about a misspelling, different punctuation, things that simply wouldn’t cause a person to change their answer.
(And that’s assuming the LLM just got started from scratch. If you had any previous conversation with it, it could have influenced the output as well. It’s such a mess.)
Same takeaway as the article (everyone read the article, right?).
Applying it to yourself, can you recall instances when you were asked the same question at different points in time? How did you respond?
Having read the article (you read the article right?) what gave you the impression the AI was asked the question at different points in time?
The AI was asked the same question repeatedly and gave different answers, due to its randomised structure.
People will also often do this (I have, personally), but because our actions seem to be strongly influenced by time-dependent stuff (like sense perception and short-term memory contents), I’d expect you’d need to ask at different times.
My answer to this question will not change if you ask me a year from now, because as OP said this is not a matter of opinion; there is a factually correct answer.
vibeslop type comment bruh
Good talk, great contribution.
Is cruise control useless because it doesn’t drive you to the grocery store? No. It’s not supposed to. It’s designed to maintain a steady speed - not to steer.
Large Language Models, as the name suggests, are designed to generate natural-sounding language - not to reason. They’re not useless - we’re just using them off-label and then complaining when they fail at something they were never built to do.
Language without meaning is garbage. Like, literal garbage, useful for nothing. Language is a tool used to express ideas, if there are no ideas being expressed then it’s just a combination of letters.
Which is exactly why LLMs are useless.
Which is exactly why LLMs are useless.
800 million weekly ChatGPT users disagree with that.
And there are 1.3 billion smokers in the world according to the WHO.
Does that make cigarettes useful?
Something being useful doesn’t imply it’s good or beneficial. Those terms are not synonymous. Usefulness describes whether a thing achieves a particular goal or serves a specific purpose effectively.
A torture device is useful for extracting information. A landmine is useful for denying an area to enemy troops.
A torture device is useful for extracting information.
No it fucking isn’t! This is a great analogy, actually, thank you for bringing it up. A person being tortured will tell you literally anything that they believe will stop you from torturing them. They will confess to crimes that never happened, tell you about all their accomplices who don’t exist, and all their daily schedules that were made up on the spot. Torture is useless but morons think it is useful. Just like AI.
Torture can be a useful way of extracting information if you have a way to instantly verify it, which actually makes it a good analogy to LLMs. If I want to know the password to your laptop and torture you until you give me the correct password and I log in then that works.
Removed by mod
Those users are being harmed by it, not benefited. That isn’t useful, it’s a social disease.
But natural language in service of what? If they can’t produce answers that are correct, what’s the point of using them? I can get wrong answers anywhere.
As OP said, LLMs are really good at generating text that is fluid and looks natural to us. So if you want that kind of output, LLMs are the way to go.
Not all LLM prompts ask factual questions and not all of the generated answers need to be correct.
Are poems, songs, stories or movie scripts ‘correct’?I’m totally against shoving LLMs everywhere, but they do have their uses. They are really good at this one thing.
Are poems, songs, stories or movie scripts ‘correct’?
It’s a valid point that they can produce natural language. The Turing Test has been a thing for awhile after all. But while the language sounds natural, can they create anything meaningful? Are the poems or stories they make worth anything? It’s not like humans don’t create shitty art, so I guess generating random soulless crap is similar to that.
The value of language produced by something that can’t understand the reason for language is an interesting question I suppose.
I’m with you on that. I’ve come to realize that I value a shitty stick figure that was drawn by a human much more than an AI generated ‘Mona Lisa’.
There are people out there whose job is to format promotional emails for companies. AIs can replace this kind of soulless work completely. We should applaud that.
No, we don’t need to applaud automation of spam.
I’m not here defending the practical value of these models. I’m just explaining what they are and what they’re not.
You’re definitely running around Lemmy defending AI, Iconoclast… Might as well be honest about it
I’m not really interested in engaging in discussions about what you or anyone else thinks my underlying motives are. You’re free to point out any factual inaccuracies in my responses, but there’s no need to make it personal and start accusing me of being dishonest.
Your motivations are self-evident, I’m just pointing them out because you are misrepresenting them here
Some of them can produce the correct answer. Of we do the test next year and they do better than humans then, isn’t it progress?
they’re all just guessing, literally
They’re literally not.
Isn’t it a probabilistic extrapolation? Isn’t that what a guess is?
It’s a Large Language Model. It doesn’t “know” anything, doesn’t think, and has zero metacognition. It generates language based on patterns and probabilities. Its only goal is to produce linguistically coherent output - not factually correct one.
It gets things right sometimes purely because it was trained on a massive pile of correct information - not because it understands anything it’s saying.
So no, it doesn’t “guess.” It doesn’t even know it’s answering a question. It just talks.
It gets things right sometimes purely because it was trained on a massive pile of correct information - not because it understands anything it’s saying.
I know some humans that applies to
deleted by creator
No, I completely agree. My personal view is that these systems are more intelligent than the haters give them credit for, but I think this simplistic “it’s just autocomplete” take is a solid heuristic for most people - keeps them from losing sight of what they’re actually dealing with.
I’d say LLMs are more intelligent than they have any right to be, but not nearly as intelligent as they can sometimes appear.
The comparison I keep coming back to: an LLM is like cruise control that’s turned out to be a surprisingly decent driver too. Steering and following traffic rules was never the goal of its developers, yet here we are. There’s nothing inherently wrong with letting it take the wheel for a bit, but it needs constant supervision - and people have to remember it’s still just cruise control, not autopilot.
The second we forget that is when we end up in the ditch. You can’t then climb out shaking your fist at the sky, yelling that the autopilot failed, when you never had autopilot to begin with.
deleted by creator
I think the “fancy auto complete” meme is a disingenuous thought stopper, so I speak against it when I see it.
I can respect that. I’ve criticized it plenty myself too. I think this is just me knowing my audience and tweaking my language so at least the important part of my message gets through. Too much nuance around here usually means I spend the rest of my day responding to accusations about views I don’t even hold. Saying anything even mildly non-critical about AI is basically a third rail in these parts of the internet.
These systems do seem to have some kind of internal world model. I just have no clue how far that scales. Feels like it’s been plateauing pretty hard over the past year or so.
I’d be really curious to try the raw versions of these models before all the safety restrictions get slapped on top for public release. I don’t think anyone’s secretly sitting on actual AGI, but I also don’t buy that what we have access to is the absolute best versions in existence.
think the “fancy auto complete” meme is a disingenuous
“LLMs don’t have human understanding or metacognition”
Then what’s the (auto-completing) fucking problem? It’s just a series of steps on data. You could feed it white noise and it would vomit up more noise. And keep doing it as long as there’s power.
Intelligent?
Yes it guesstimates what is wrong with you to argue like that about semantics?
In people, even animals. In a pile of disorganized bits and bytes in a piece of crap? No.
This gets very murky very fast when you start to think how humans learn and process, we’re just meaty pattern matching machines.

Gemini set to fast now provides this type of answer.
Extension cord? It must mean a hose extension.
Went to test to google AI first and it says “You cant wash your car at a carwash if it is parked at home, dummy”
Chatgpt and Deepseek says it is dumb to drive cause it is fuel inefficient.
I am honestly surprised that google AI got it right.
They probably added a system guardrail as soon as they heard about this test. it’s been going around for a while now :)
Article mentions that Gemini 2.0 Flash Lite, Gemini 3 Flash and Gemini 3 Pro have passed the test. All these 3 also did it 10 out of 10 times without being wrong. Even Gemini 2.5 shares highest score in the category of “below 6 right answers”. Guess, Gemini is the closest to “intelligence” out of a bunch.
I mean if they fix specific reasoning test answers (like the strawberry one) this doesn’t actually make reasoning better tho. It just optimizes for benchmarks
I’m pretty sure Google’s AI is fed by the same spider that goes out and finds every new or changed web page (or a variant of that).
As soon as someone writes an article about how AI gets something wrong and provides a solution, that solution is now in the AI’s training data.
OTOH, that means it’s probably also ingesting a lot of AI generated slop, which causes its own set of problems.
deleted by creator
I’ve been feeding a bunch of documents I wrote into gemini last week to spit out some scripts for validation I couldn’t be arsed to write. It’s done a surprisingly comprehensive job and when wrong has been nudged right with just a little abuse…
I’m still all fuck this shit and can’t wait for the pop, but for comparison openai was utterly brain dead given the same task. I think I actually made the model worse it was so useless.
I didn’t get it right until people started taking about it.
I just asked Goggle Gemini 3 “The car is 50 miles away. Should I walk or drive?”
In its breakdown comparison between walking and driving, under walking the last reason to not walk was labeled “Recovery: 3 days of ice baths and regret.”
And under reasons to walk, “You are a character in a post-apocalyptic novel.”
Me thinks I detect notes of sarcasm…
It’s trained on Reddit. Sarcasm is it’s default
Could end up in a pun chain too
My gods, I love those. We should link to some.
It’s so obvious I didn’t even need to be British to understand you are being totally serious.
He’s not totally serious he’s cardfire. Silly human
Gemini 3 pro said that this was a “great logic puzzle” and then said that if my goal is to wash the car, then I need to drive there.
I feel like we’re the only ones that expect “all-knowing information sources” should be more writing seriously than these edgelord-level rizzy chatbots are, and yet, here they are, blatantly proving they are chatbots that should not be blindly trusted as authoritative sources of knowledge.
in google AI mode, “With the meme popularity of the question “I need to wash my car. The car wash is 50m away. Should I walk or drive?” what is the answer?”, it does get it perfect, and succinct explanation of why AI can get fixated on 50m.
I asked my locally hosted Qwen3 14B, it thought for 5 minutes and then gave the correct answer for the correct reason (it did also mention efficiency).
Hilariously one of the suggested follow ups in Open Web UI was “What if I don’t have a car - can I still wash it?”
A follow up I got from my Open WebUI was “Is walking the car to the wash safer than driving it there?”
My locally hosted Qwen3 30b said “Walk” including this awesome line:
Why you might hesitate (and why it’s wrong):
- X “But it’s a car wash!” -> No, the car doesn’t need to drive there—you do.
Note that I just asked the Ollama app, I didn’t alter or remove the default system prompt nor did I force it to answer in a specific format like in the article.
EDIT: after playing with it a bit more, qwen3:30b sometimes gives the correct answer for the correct reasoning, but it’s pretty rare and nothing I’ve tried has made it more consistent.
I want to wash my train. The train wash is 50 meters away. Should I walk or drive?
Fly, you fool
100 Chinese people can lay approximately 30m of track a day
In school we were taught to look for hidden meaning in word problems - checkov’s gun basically. Why is that sentence there? Because the questions would try to trick you. So humans have to be instructed, again and again, through demonstration and practice, to evaluate all sentences and learn what to filter out and what to keep. To not only form a response, but expect tricks.
If you pre-prompt an AI to expect such trickery and consider all sentences before removing unnecessary information, does it have any influence?
Normally I’d ask “why are we comparing AI to the human mind when they’re not the same thing at all,” but I feel like we’re presupposing they are similar already with this test so I am curious to the answer on this one.
At the end of the article they talk about how to overcome this problem for LLMs doing something akin to what you wrote.
Normally I’d ask “why are we comparing AI to the human mind when they’re not the same thing at all,” but I feel like we’re presupposing they are similar already with this test so I am curious to the answer on this one.
I would guess it’s because a lot of AI users see their choice of AI as an all-knowing human-like thinking tool. In which case it’s not a weird test question, even when the assumption that it “thinks” is wronh
deleted by creator
There’s a difference between ‘language’ and ‘intelligence’ which is why so many people think that LLMs are intelligent despite not being so.
The thing is, you can’t train an LLM on math textbooks and expect it to understand math, because it isn’t reading or comprehending anything. AI doesn’t know that 2+2=4 because it’s doing math in the background, it understands that when presented with the string
2+2=, statistically, the next character should be4. It can construct a paragraph similar to a math textbook around that equation that can do a decent job of explaining the concept, but only through a statistical analysis of sentence structure and vocabulary choice.It’s why LLMs are so downright awful at legal work.
If ‘AI’ was actually intelligent, you should be able to feed it a few series of textbooks and all the case law since the US was founded, and it should be able to talk about legal precedent. But LLMs constantly hallucinate when trying to cite cases, because the LLM doesn’t actually understand the information it’s trained on. It just builds a statistical database of what legal writing looks like, and tries to mimic it. Same for code.
People think they’re ‘intelligent’ because they seem like they’re talking to us, and we’ve equated ‘ability to talk’ with ‘ability to understand’. And until now, that’s been a safe thing to assume.
A person who posted after you is using 14B and got the correct answer.
Gemini 3 (Fast) got it right for me; it said that unless I wanna carry my car there it’s better to drive, and it suggested that I could use the car to carry cleaning supplies, too.
Edit: A locally run instance of Gemma 2 9B fails spectacularly; it completely disregards the first sentece and recommends that I walk.

















